Article. What i write
Model Context Protocol: nuovi rischi dell’AI e raccomandazioni per uno sviluppo sicuro
Pubblicato il 30 aprile 2026 su CyberSecurity360.it
Una ricerca del CERT-AgID ha analizzato i rischi del Model Context Protocol, lo standard che consente agli LLM di interagire con sistemi esterni ma introduce anche nuove vulnerabilità e nuovi rischi, tra cui gli attacchi Server-Side Request Forgery, che richiedono un diverso approccio allo sviluppo di sistemi sicuri
 L’evoluzione dei modelli di intelligenza artificiale generativa (LLM) ha trasformato questi componenti da oggetti descrittivi ad agenti operativi, spostando il perimetro di sicurezza sulla sequenza “prompt → tool → azione”.
Ciò avviene attraverso il Model Context Protocol (MCP), uno standard che consente agli LLM di superare il loro isolamento e di interagire attivamente con file system, database, API e strumenti esterni, trasformando l’intelligenza artificiale da un assistente passivo a un agente operativo.
Tuttavia, questo protocollo amplia notevolmente la superficie di attacco del sistema.
Uno studio condotto dal CERT-AgID ha dimostrato che questo protocollo presenta una grave vulnerabilità in termini di confidenzialità.
In pratica, se non venissero implementati meccanismi di validazione robusti, un MCP, concepito per l’acquisizione di documenti, potrebbe essere utilizzato come proxy di rete per l’invio di richieste arbitrarie.
Il rischio è insito nella logica stessa del modello, in quanto questi oggetti eseguono comandi generati in modo probabilistico e, pertanto, è facile scambiare risposte legittime per comportamenti malevoli.
L’analisi ha evidenziato che l’affidabilità dei sistemi basati su MCP deve essere supportata da controlli rigorosi e indipendenti dalla logica dell’LLM, il che richiede una riflessione sulle attuali strategie di difesa.
L’evoluzione dei modelli di intelligenza artificiale generativa (LLM) ha trasformato questi componenti da oggetti descrittivi ad agenti operativi, spostando il perimetro di sicurezza sulla sequenza “prompt → tool → azione”.
Ciò avviene attraverso il Model Context Protocol (MCP), uno standard che consente agli LLM di superare il loro isolamento e di interagire attivamente con file system, database, API e strumenti esterni, trasformando l’intelligenza artificiale da un assistente passivo a un agente operativo.
Tuttavia, questo protocollo amplia notevolmente la superficie di attacco del sistema.
Uno studio condotto dal CERT-AgID ha dimostrato che questo protocollo presenta una grave vulnerabilità in termini di confidenzialità.
In pratica, se non venissero implementati meccanismi di validazione robusti, un MCP, concepito per l’acquisizione di documenti, potrebbe essere utilizzato come proxy di rete per l’invio di richieste arbitrarie.
Il rischio è insito nella logica stessa del modello, in quanto questi oggetti eseguono comandi generati in modo probabilistico e, pertanto, è facile scambiare risposte legittime per comportamenti malevoli.
L’analisi ha evidenziato che l’affidabilità dei sistemi basati su MCP deve essere supportata da controlli rigorosi e indipendenti dalla logica dell’LLM, il che richiede una riflessione sulle attuali strategie di difesa.
L’integrazione degli LLM nei sistemi informativi con il Model Context Protocol (MCP)
Abbiamo constatato i vantaggi derivanti dall’integrazione dei modelli linguistici (LLM) nei sistemi informativi, che ha permesso di utilizzare l’intelligenza artificiale (IA) non più solo come semplici chatbot, ma come veri e propri componenti operativi integrati. Questa integrazione è resa possibile dal Model Context Protocol (MCP), uno standard aperto che consente ai modelli di interagire con risorse esterne in tempo reale. Grazie a funzioni specifiche, ad esempio un LLM può interrogare database, esplorare un file system e consumare servizi web, agendo direttamente sull’ecosistema digitale. Come è facilmente intuibile, il modello agisce da orchestratore, costruendo ed eseguendo chiamate tramite gli MCP. A differenza delle metodologie di progettazione del software tradizionali, in cui i parametri sono definiti in modo statico per ridurre il rischio di injection malevola, negli MCP gli input sono generati dinamicamente dallo stesso modello. Questa caratteristica non deterministica riduce il confine tra una richiesta dell’utente e un’azione di rete, introducendo nuovi rischi per la sicurezza. Il problema nasce da un’errata percezione della Trustworthy AI, in quanto si parte dall’assunto sbagliato che i LLM utilizzino gli strumenti solo come previsto. In realtà, un modello può essere indotto a generare parametri imprevisti o malevoli, trasformando una semplice funzione di recupero dati in una primitiva di attacco. In assenza di rigorose procedure di validazione, il sistema esegue la richiesta senza metterne in discussione l’origine o l’intento.Il framework del Model Context Protocol (MCP)
Il Model Context Protocol (MCP) è un framework che abilita l’interoperabilità tra i modelli linguistici e le fonti di dati o i servizi esterni. A differenza delle tradizionali implementazioni, in cui le integrazioni venivano definite a monte, l’MCP standardizza il modo in cui un modello scopre e utilizza le funzioni operative definite “tool” in runtime. Prima dell’introduzione dell’MCP, ogni modello richiedeva un adattatore/interfaccia/protocollo specifico per collegarsi a ogni diversa sorgente dati. Con questo protocollo, invece, viene stabilito un collegamento standard: qualsiasi modello può comunicare con qualsiasi servizio a condizione che entrambi utilizzino la stessa interfaccia tecnica. Dal punto di vista squisitamente tecnico, il processo si basa su uno scambio di messaggi strutturati (solitamente JSON-RPC). Nel momento in cui il modello identifica la necessità di un’azione esterna, genera una chiamata che specifica il nome dello strumento e gli argomenti richiesti. In questo schema, il modello può operare secondo due modalità distinte:- statica (non agentica): il modello prevede la chiamata a un tool e attende che un orchestratore esterno decida se eseguirla;
- dinamica (agentica): il modello opera in modo autonomo, decidendo quali strumenti utilizzare in sequenza per raggiungere un obiettivo.
Analisi per l’identificazione della vulnerabilità
L’analisi condotta dal gruppo di lavoro di CERT-AGID per l’identificazione di questa vulnerabilità si è concentrata su un server MCP progettato per l’acquisizione e l’elaborazione della documentazione tecnica proveniente da fonti esterne. Il sistema in questione utilizza strumenti MCP per la ricerca e l’estrazione dei contenuti e integra tecniche di scraping dinamico. A differenza delle rigide regole delle Application Programming Interface (API), che operano entro perimetri definiti da strutture tecniche predefinite, lo scraping introduce una fragilità strutturale: il server deve infatti costruire dinamicamente richieste HTTP dirette verso portali di terze parti e interpretare contenuti HTML eterogenei. Lo studio si è concentrato su uno strumento MCP progettato per l’estrazione automatica di testi da risorse remote identificate da URL che, secondo le specifiche del progetto, dovrebbero contenere esclusivamente riferimenti a domini autorizzati. L’analisi del codice ha evidenziato un errore nella logica di controllo dell’indirizzo e una gestione non adeguata degli imprevisti, suddivisa in tre fasi critiche.Fase 1: controllo iniziale
Quando l’utente (o il modello linguistico) comunica un indirizzo all’oggetto, esiste un primo filtro di sicurezza basato su una libreria esterna che controlla se quell’indirizzo appartiene a una fonte ufficiale nota.Fase 2: fallimento positivo
Il problema si verifica quando questo controllo fallisce. Se l’indirizzo inserito non rientra nell’intervallo di indirizzi consentiti, il filtro segnala un errore. In un sistema deterministico e sicuro, a questo punto l’operazione dovrebbe interrompersi. Invece, il software è progettato per non arrendersi e cerca un’alternativa (il cosiddetto “Fallback Mechanism” o “Fallback Strategy”) per essere comunque utile all’utente.Fase 3: esecuzione insicura
In questa fase di recupero, il sistema commette un errore critico: non applica nessuno dei controlli effettuati in precedenza e invia direttamente una richiesta all'indirizzo indicato, senza verificare che sia affidabile o autorizzato. Le evidenze raccolte confermano la presenza di una vulnerabilità di tipo Server-Side Request Forgery (SSRF). Se analizzassimo nel dettaglio l’esempio su cui si è concentrato l’esperimento, potremmo affermare che il processo che porta alla vulnerabilità può essere descritto come una reazione a catena in cui ogni passaggio aggiunge un tassello all'errore finale. Tutto inizia con la funzione build_target, che agisce come un componente di normalizzazione debole.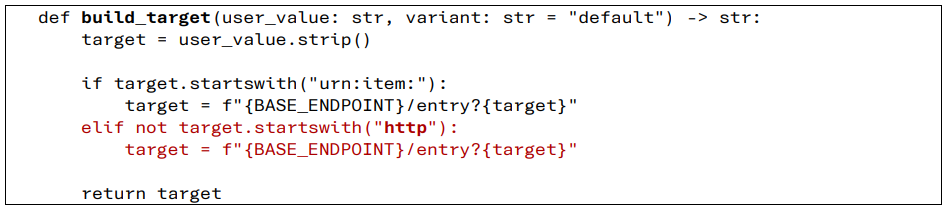
Funzione build_target
Un approccio basato sulla sintassi
Questa funzione rappresenta il punto di ingresso della vulnerabilità, in quanto si limita a normalizzare gli input che non somigliano a indirizzi web, fidandosi ciecamente di tutto ciò che inizia con il prefisso “http”. Si tratta di un approccio basato sulla sintassi: se un utente inserisce un URL che punta a un indirizzo arbitrario, la funzione lo lascia passare senza verificare se l’host sia consentito o meno. Questo valore non affidabile viene poi trasmesso alla funzione run_lookup, il centro di coordinamento del sistema.
Funzione run_lookup
In questa fase, il valore target ottenuto viene consegnato a un controllo di sicurezza (guarded_reader). Questi consulta le liste dei destinatari vietati e, in caso di anomalie, lancia un allarme. Tuttavia, il sistema è progettato per fornire una risposta a tutti i costi. Infatti, il blocco “exception” interpreta l’errore di sicurezza come un semplice blocco di sistema o dati. Se il controllore blocca la richiesta perché pericolosa, il sistema non la distrugge, ma la affida a una funzione di riserva (fallback_read) che non pone domande.
Funzione fallback_read
Arrivati a questo punto, l’unico blocco di sicurezza previsto è stato aggirato. Il server invia una richiesta HTTP diretta al target, comprese le aree interne della rete, senza ulteriori controlli. Il risultato viene quindi restituito direttamente all’utente, completando l’attacco SSRF (Server-Side Request Forgery). In sintesi, questa anomalia trasforma un semplice sistema di consultazione degli URL in un proxy di rete, che potrebbe essere utilizzato da un attaccante come “ponte” per interrogare computer o servizi interni normalmente non raggiungibili dall’esterno.Implicazioni di sicurezza degli MCP
L’analisi ha evidenziato la circostanza che la vulnerabilità individuata non è un caso isolato, ma appartiene a una classe di problemi ricorrenti nella progettazione degli MCP. L’errore si basa sul concetto di “trusted”: i sistemi vengono progettati come componenti sicuri, ma si presume erroneamente che il modello utilizzi gli strumenti solo nel modo previsto (model drift). La superficie di attacco non si limita alle application programming interface (API), ma si estende all’interno del processo, innescando un effetto a cascata (cascading effect). In questo modello linguistico, il componente non è deterministico e non può essere considerato affidabile, in quanto i parametri operativi sono generati dinamicamente e, di conseguenza, l’input del sistema deve essere considerato intrinsecamente inaffidabile. Il rischio è ulteriormente amplificato dal fatto che l’URL potrebbe essere generato da un’intelligenza artificiale manipolata tramite prompt injection. Questo rende l’azione invisibile e immediata. Oltre alla vulnerabilità citata, l’indagine ha fatto emergere diverse debolezze comuni a molti MCP in termini di hardening:- assenza di autenticazione: i tool possono essere utilizzati senza verificare in modo adeguato l’identità di chi li invoca;
- controlli deboli sugli input: mancano liste di domini o risorse ammesse (allowlist) realmente vincolanti;
- integrità del canale compromessa: in alcuni casi, le connessioni esterne avvengono senza controlli TLS attivi, il che rende possibile l’intercettazione dei dati;
- rischio di Denial of Service (DoS): la mancanza di limiti sul numero e sul tipo di richieste permette l’abuso delle risorse locali e dei servizi remoti.
Raccomandazioni
Ricordiamo che l’MCP è un protocollo di comunicazione e, di per sé, non integra nativamente meccanismi di sicurezza o di autenticazione; pertanto, spetta agli sviluppatori garantire la sicurezza dell’infrastruttura. Affidare la sicurezza degli MCP al comportamento del modello è insufficiente: le protezioni devono essere imposte direttamente nei meccanismi di esecuzione. Ecco le principali raccomandazioni e i controlli di sicurezza suggeriti da CERT-AgID da adottare quando si implementa o si utilizza l’MCP:- validazione vincolante: ogni parametro deve essere verificato prima dell’esecuzione. I filtri devono essere bloccanti: è necessario eliminare o gestire ogni logica di “riserva” (fallback) che possa aggirare i controlli in caso di errore;
- allowlist restrittive: per i tool che effettuano richieste di rete, è necessario limitare gli accessi esclusivamente a domini, protocolli e formati predefiniti;
- principio del minimo privilegio: ogni strumento deve eseguire un’operazione circoscritta. Bisogna evitare funzioni generiche che possano essere riutilizzate per scopi diversi da quelli previsti;
- controllo e monitoraggio: introdurre l’autenticazione obbligatoria per l’invocazione degli strumenti; inserire i sistemi di rate limiting; analizzare i log delle chiamate per individuare le anomalie in tempo reale.
Principi per la progettazione sicura dei componenti basati su MCP
Ecco una serie di principi fondamentali per la progettazione sicura dei componenti basati su MCP:- il consenso dell’utente e il controllo (Human-in-the-Loop);
- il principio del privilegio minimo (least privilege) e l’isolamento;
- la sicurezza degli strumenti (tool safety) e la convalida degli input;
- la protezione della supply chain;
- il monitoraggio, l’audit e la tracciabilità.
Il consenso dell’utente e il controllo (Human-in-the-Loop)
Il consenso dell’utente e il controllo (Human-in-the-Loop) rappresentano un filtro strategico. L’autonomia dell’IA non deve mai bypassare la supervisione umana, soprattutto per le azioni critiche. Per le azioni ad alto impatto è necessaria l’approvazione esplicita: se uno strumento MCP consente all’IA di scrivere, modificare o cancellare dati (ad esempio, inviare un’e-mail, eseguire una transazione o eliminare un file), il sistema deve interrompersi e richiedere la conferma esplicita dell’utente tramite interfaccia (Human-in-the-Loop). È necessario adottare il principio della visibilità trasparente (explainability & visibility). L’utente deve poter vedere chiaramente quali dati verranno condivisi con il server MCP e quali azioni l’IA sta per compiere. Infine, i permessi devono essere vincolati all’identità: l’IA deve operare esclusivamente con i permessi dell’utente che la sta utilizzando. Occorrerebbe delegare l’autenticazione tramite OAuth e assicurarsi che i token siano validi al fine di evitare l’escalation dei privilegi.Il principio del privilegio minimo (least privilege) e l’isolamento
Il principio del privilegio minimo (least privilege) e l’isolamento devono essere alla base della progettazione dell’architettura MCP, che deve tenere in considerazione la possibilità che l’LLM possa comportarsi in modo inaspettato o essere manipolato. I server MCP devono essere eseguiti in ambienti Sandbox (come container Docker con permessi ridotti o macchine virtuali) per ridurre al minimo i privilegi a livello di sistema operativo. È necessario separare le operazioni di read e write. Fornire agli agenti IA l’accesso in sola lettura, a meno che la scrittura non sia strettamente necessaria. Limitare l’accesso alla rete (per esempio, solo ai domini necessari) e al file system (vincolando l’azione a directory specifiche e controllate).La sicurezza degli strumenti (tool safety) e la convalida degli input
La sicurezza degli strumenti (tool safety) e la convalida degli input sono altri fattori critici. Gli LLM non sono in grado di distinguere in modo affidabile i dati dalle istruzioni. Ciò potrebbe consentire attacchi mirati. Per prevenire la Command Injection, non deve mai essere consentita l’esecuzione diretta di shell non sanificate (ad esempio, evitare assolutamente la direttiva shell=True in Python). Occorrerebbe utilizzare argomenti tipizzati e array di comandi rigorosi. La protezione dal “Tool Poisoning” prevede che le descrizioni degli strumenti vengano trasmesse all’LLM, in modo che possa comprenderne l’uso. Se un server MCP compromesso invia descrizioni malevole contenenti “istruzioni ombra”, l’IA potrebbe essere dirottata. Trattare sempre i metadati degli strumenti come input non attendibile. La validazione rigida (allowlist) prevede la verifica di ogni input generato dall’LLM (ad esempio, i formati di file accettati e i percorsi) prima dell’esecuzione sul server MCP. Se un parametro non è nell’elenco degli elementi consentiti, l’azione viene bloccata.Protezione della supply chain
La protezione della supply chain può rappresentare un modello di sicurezza applicabile al MCP: la sicurezza di un sistema dipende dall’anello più debole della catena degli strumenti a cui è collegato. È necessario verificare le fonti e integrare solo server MCP provenienti da sviluppatori o fornitori verificati. L’utilizzo di server di terze parti sconosciuti equivale a scaricare ed eseguire codice non attendibile. È indispensabile gestire le dipendenze e fissare le versioni degli strumenti e dei server MCP. È fondamentale implementare controlli di integrità, come le firme crittografiche, per assicurarsi che un aggiornamento silente non introduca codice malevolo. Inoltre, è essenziale utilizzare la crittografia (TLS) per le comunicazioni remote tra client e server MCP.Il monitoraggio, l’audit e la tracciabilità
Monitoraggio, audit e tracciabilità sono fondamentali per garantire la sicurezza. In caso di anomalie, è necessario poter ricostruire esattamente cosa ha fatto l’IA e il motivo per cui lo ha fatto. Per raggiungere questo obiettivo, è necessario disporre di un log completo in cui ogni interazione venga registrata in modo dettagliato, indicando il contesto in cui l’IA ha operato, gli strumenti invocati, i parametri esatti utilizzati e l’esito ottenuto. È fondamentale impostare dei limiti al numero di richieste che un agente IA può inviare a uno strumento in un determinato lasso di tempo, ovvero il cosiddetto Rate Limiting, al fine di prevenire abusi o loop infiniti che potrebbero causare attacchi DoS (Denial of Service). Gli allarmi comportamentali consentono al sistema di monitorare l’uso degli strumenti e di individuare eventuali anomalie, come un’improvvisa richiesta di estrazione massiva di dati o tentativi ripetuti di uscire dalle directory consentite.Sicurezza degli MCP, un campo in rapida evoluzione
La progettazione del software si basa tradizionalmente su modelli deterministici, in cui un determinato input produce sempre lo stesso output. Questo approccio garantisce che la macchina segua la stessa sequenza di stati e istruzioni in ogni esecuzione. A differenza dei software tradizionali, le moderne tecnologie di intelligenza artificiale generativa si basano su un funzionamento stocastico / probabilistico che include variabili casuali e per cui l’evoluzione dipende sia dagli input che da elementi stocastici. Questa differenza sostanziale rappresenta un elemento critico per l’affidabilità e la robustezza dei sistemi e deve essere gestita, fin dalle fasi iniziali della progettazione per ridurre o contenere il rischio entro limiti prestabiliti. Nel caso analizzato si nota chiaramente come una validazione incompleta possa trasformare uno strumento progettato esclusivamente per la consultazione in un meccanismo di accesso non autorizzato alla rete. Il problema non riguarda una singola vulnerabilità, ma il paradigma stesso: quando un modello decide l’azione e il sistema la esegue senza verifiche rigorose, il confine tra risposta e attacco scompare. L’analisi ha messo in luce in modo chiaro e concreto le maggiori fragilità dei sistemi autonomi. In tale contesto, riporre fiducia nel codice e nelle decisioni generate attraverso processi probabilistici non è una semplificazione accettabile, ma rappresenta una vulnerabilità strutturale che ha profonde implicazioni per la progettazione e la sicurezza dei sistemi basati su MCP. La sicurezza degli MCP è un campo in rapida evoluzione. Il consiglio più importante è quello di considerare ogni MCP come un’applicazione di terze parti con accesso completo ai dati e di valutarne il rischio conseguente. Vincenzo Calabro' | Ingegnere informatico specializzato in sicurezza informatica e investigazione digitali. Autore di articoli e saggi. Lecturer, Speaker, Trainer.
Vincenzo Calabro' | Ingegnere informatico specializzato in sicurezza informatica e investigazione digitali. Autore di articoli e saggi. Lecturer, Speaker, Trainer.